Are you looking for tricky Embedded C interview questions to ace your next job interview? If your answer “YES”, then You are in the right place!
This guide covers the most commonly asked Embedded C questions, helping both freshers and experienced professionals prepare for technical interviews. The best part? These Embedded C interview questions and answers are free, and you can also download them in PDF format for offline practice.
Why This Guide?
After the success of my previous post on C Interview Questions, many readers requested a dedicated Embedded C interview guide. This article is a result of that demand.
In this guide, you’ll find:
✅ Essential Embedded C interview questions
✅ Tricky and advanced questions for experienced developers
✅ Unsolved Embedded C questions to test your skills
💡 “Success is the sum of small efforts, repeated day-in and day-out.” — Robert Collier
Now, let’s dive straight into the top Embedded C interview questions without wasting time!
Embedded C Interview Questions for Experienced & Freshers:
Q) What is the volatile keyword?
A volatile keyword is a “type qualifier” that prevents the objects, from compiler optimization and tells the compiler that the value of the object can change at any time without any action being taken by the code. This type of scenario happens in case multi-threading, interrupts or accessing the GPIO, …etc., where the object may be changed by external processes or events.
Let’s understand it with an example,
Consider a situation where sensorValue is an integer variable and its value getting updated by an ISR.
int sensorValue = 0;
while (sensorValue== 0)
{
// Some code
}
If you will not use the volatile qualifier with sensorValue compiler will optimize the above code and might remove your while loop because it may think it always be true.
The volatile qualifier here helps you and it instruct compiler not to optimize the code related to this sensorValue, ensuring that every time the variable is accessed, it reads the actual value from memory rather than relying on a cached value.
volatile int sensorValue;
while (sensorValue== 0)
{
// Some code
}
Note: C standards say that if an object that has volatile-qualified type may be modified in ways unknown to the implementation or have other unknown side effects.
Q) What is the use of volatile keyword?
The volatile keyword is used to instruct compiler not to optimize the code related volatile identifier and ensure that that every time the code reads the actual value of the variable from memory instead of using a previously cached value.
Some common places where volatile keyword is uses:
- Accessing Hardware Registers:
Ex: Getting the value from a hardware device register that is updated by an external event.
volatile uint32_t* const pHardwareRegister = (uint32_t*)0x00020000; // You always get the latest value from memory uint32_t value = *pHardwareRegister;
- Multithreading/Concurrency:In multi-threaded applications, if a variable is shared between multiple threads, it must be declared volatile, as this ensures that each thread reads the most up-to-date value.
- Interrupt Handlers:
Consider a scenario where a flag is modified within an interrupt service routine (ISR) and accessed in the main code. In that case flag must be declared volatile to prevent the compiler optimization. See the below example code,
volatile int interruptFlag = 1;
// In the interrupt handler
void ISR()
{
interruptFlag = 0;
}
int main()
{
While(1)
{
while (!interruptFlag)
{
// Do something when ISR comes
interruptFlag = 1;
}
}
}
Q) What is the difference between the const and volatile qualifiers in C?
Both const and volatile are “type qualifier” in C but they use for different purposes.
The const keyword is compiler-enforced and says that the program could not change the value of the object that means it makes the object nonmodifiable type. Let us see an example,
const int a = 0; // Error: Cannot modify a constant variable a = 10;
If you try to modify the value of “a”, you will get the compiler error because “a” is qualified with const keyword that prevents to change the value of the”a” (integer variable).
Another side, volatile prevents any compiler optimization and says that the value of the object may change at any time due to external events that is beyond the control of the program and so that compiler will not make any assumption about the object. Let see an example,
volatile int sensorValue;
while (sensorValue== 0)
{
// Some code
}
In the above code compiler is instructed not to optimize accesses to volatile variables “sensorValue”. The volatile keyword ensures that the code always reads the “sensorValue” from memory and does not rely on any cached values.
See the below table for better understanding: –
| Aspect | const | volatile |
|---|---|---|
| Purpose | Prevents modification of a variable. | Prevents compiler from optimizing variable accesses. |
| Optimization | Allows compiler optimizations based on immutability. | Disables certain optimizations, forces fresh reads from memory. |
| Use Case | For variables that should not be changed. Like Constants, function parameters that shouldn’t be modified.
Example, const int a = 10; void foo(const int *ptr); |
For variables that can change due to external factors. Like Hardware registers, interrupt flags, shared variables in multithreading.
Example, volatile int a = 0; |
Q) Can a variable be both const and volatile in C?
Yes, you can use both const and volatile together. A common use case for combining these keywords is when accessing the GPIO registers.
For example, if a GPIO pin is configured as an input, then its value may change due to external factors (like a switch or another connected device). In this case volatile ensures that the compiler always reads the current value directly from the GPIO address, preventing any assumptions or optimizations.
But only using of volatile keyword is not sufficient, there is one another potential issue: if the pointer (PortRegister) is not constant, the program could accidentally modify the pointer’s address. It would be a nightmare issue, so to prevent this issue, you need to declare the pointer as const while also using volatile to ensure proper and consistent access to the GPIO port values. Here, const indicates that the program itself cannot modify the value.
Syntax of declaration,
int volatile * const PortRegister;
How to read the above declaration,
int volatile * const PortRegister; | | | | | | | | | +------> PortRegister is a | | | +-----------> constant | | +---------------> pointer to a | +---------------------> volatile +---------------------------> integer
Q) What do you understand by startup code?
Startup code generally written in assembly (or may be low-level C), that executes before the main function. When the system boots up, the startup code is the first to run. It sets up memory configurations (such as initializing RAM sections and the stack) and prepares hardware components, making the platform ready to call the main function.
There are some Key responsibilities of startup code: –
- Stack Memory Setup: Initializes the stack pointer.
- Heap Memory Setup: Initializes the heap, if dynamic memory is used.
- Data Segment Initialization: Copies initialized data from ROM to RAM and clears the BSS section for uninitialized global and static variables.
- Interrupt Vector Table Setup: Sets up the table that links hardware interrupts and exceptions to their corresponding handlers.
- Reset Handler Code: Provides the entry point that runs when the system is powered on or reset.
- Other Exception Handler Code: Configures handlers for faults or exceptions like hard faults, memory faults, etc.
- Calling the Main Function: In the last when everything setup, it jumps to the main function.
Q) What is the role of the interrupt vector table in startup code?
An interrupt vector table (IVT) is a data structure that holds the addresses of interrupt service routines (ISRs). IVT initializes in the startup code and ensure that the correct ISR is invoked when a specific interrupt occurs.
Q) What is ISR?
An ISR refers to the Interrupt Service Routines. These are procedures stored at specific memory addresses which are called when a certain type of interrupt occurs. The Cortex-M processors family has the NVIC that manages the execution of the interrupt.
Q) Can we pass any parameter and return a value from the ISR (Interrupt Service Routine)?
An ISR neither returns a value nor allows parameters to be passed.
Now you are thinking why??
The reason is that an ISR is triggered by a hardware or software event, not explicitly called by the program code. As a result, there’s no mechanism to pass arguments to an ISR like a regular function.
Also, since the ISR is not called directly by code, there’s no calling function that can capture a return value from it. This is why ISRs do not return values.
Q) What is interrupt latency?
Interrupt latency is the number of clock cycles taken by the processor to respond to an interrupt request. It is measured as the number of clock cycles between the assertion of the interrupt request and the execution of the first instruction in the interrupt handler.
In other words, interrupt latency is the time delay between the generation of an interrupt signal and the execution of the first instruction in the corresponding interrupt service routine (ISR).
Example,
Interrupt Signal Generated ----------- First ISR Instruction Executed
^
|
Latency
Interrupt Latency on the Cortex-M processor family
The Cortex-M processors have very low interrupt latency. In the below table, I have mentioned, Interrupt latency of Cortex-M processors with zero wait state memory systems.
| Processors | Cycles with zero wait state memory |
| Cortex-M0 | 16 |
| Cortex-M0+ | 15 |
| Cortex-M3 | 12 |
| Cortex-M4 | 12 |
| Cortex-M7 | 12 |
Q) How do you measure interrupt latency?
Using the Oscilloscope you can measure the Interrupt Latency, see the below steps:
1. Setup GPIO Pins:
- One GPIO for Interrupt Generation: Configure one GPIO pin as an input to trigger the interrupt.
- One GPIO for Toggling: Configure a second GPIO pin as an output that will toggle at the start of the interrupt service routine (ISR). If you want; you can also be connected to an LED for visual.
2. Monitor Signals:
Connect the oscilloscope probes:
- Probe 1: Attach to the interrupt-generating GPIO pin.
- Probe 2: Attach to the GPIO pin configured for toggling (or the LED output).
3. Trigger the Interrupt:
- Generate the interrupt signal on the configured GPIO.
4. Capture the Signals:
- When you generate the interrupt, both signals will change simultaneously.
- The oscilloscope will display both waveforms, allowing you to visualize the timing of the interrupt signal and toggled signals’ timing.
5. Measure Interrupt Latency:
Now at the end measure the interrupt latency following the below steps.
- Observe the time interval between the rising edge of the interrupt signal (Probe 1) and the rising edge of the toggled signal (Probe 2).
- The time difference between these two events represents the interrupt latency, which can be directly measured using the oscilloscope’s measurement tools.
Q) How to reduce interrupt latency?
The interrupt latency depends on many factors, some factors I am mentioning in the below statements.
- Platform and interrupt controller.
- CPU clock speed.
- Timer frequency.
- Context Switching Time
- Cache configuration.
- Application program.
So using the proper selection of platforms and processors we can easily reduce the interrupt latency. We can also reduce the interrupt latency by making the ISR shorter and avoid to calling a function within the ISR.
Q) Is it safe to call printf() inside Interrupt Service Routine (ISR)?
It is not a good idea to call the printf() insider the ISR. The printf function is not reentrant, thread safe.
Q) Can we put a breakpoint inside ISR?
Putting a breakpoint inside ISR is not a good idea.
Q) Why are interrupts disabled during system initialization in startup code??
It is not mandatory to disable interrupts during system initialization; it depends on the system design. However, it is generally advisable to disable interrupts during the system initialization to prevent any interrupt from occurring while the system is in an uninitialized state, which could lead to unpredictable behavior. Once the system is completely initialized and stable, we re-enable them to allow normal program execution and event handling.
Q) Explain the interrupt execution sequence?
Q) What is the difference between an uninitialized and a null pointer?
An uninitialized pointer is a pointer that points to an unknown memory location. The behavior of an uninitialized pointer is undefined. The code’s behavior is undefined if you try to dereference an uninitialized pointer.
According to the C standard, an integer constant expression with the value 0, or such an expression cast to type void*, is called a null pointer constant. The behavior of dereferencing a null pointer is defined and will typically cause the program to crash (or trigger a segmentation fault).
Example,
int *ptr; // Uninitialized pointer int *ptr = NULL; // Null pointer
Q) What are the causes of Interrupt Latency?
- The first delay is typically caused by hardware: The interrupt request signal needs to be synchronized to the CPU clock. Depending on the synchronization logic, up to 3 CPU cycles may expire before the interrupt request has reached the CPU core.
- The CPU will typically complete the current instruction, which may take several cycles. On most systems, divide, push-multiple or memory-copy instructions are the most time-consuming instructions to execute. On top of the cycles required by the CPU, additional cycles are often required for memory accesses. In an ARM7 system, the instruction STMDB SP!,{R0-R11, LR} typically is the worst-case instruction, storing 13 registers of 32-bits each to the stack, and takes 15 clock cycles to complete.
- The memory system may require additional cycles for wait states.
- After completion of the current instruction, the CPU performs a mode switch or pushes registers on the stack (typically PC and flag registers). Modern CPUs such as ARM generally perform a mode switch, which takes fewer CPU cycles than saving registers.
- Pipeline fill: Most modern CPUs are pipelined. Execution of an instruction happens in various stages of the pipeline. An instruction is executed when it has reached its final stage of the pipeline. Since the mode switch has flushed the pipeline, a few extra cycles are required to refill the pipeline.
Q) Can we use any function inside ISR?
Yes, you can call a function within an ISR (Interrupt Service Routine), but it is not recommended because it can increase interrupt latency and degrade the system’s performance. If you want to call a nested function within the ISR, you need to consult the datasheet of your microcontroller, as some vendors impose limits on how many function calls can be nested within an ISR.
One important point to remember is that the function called from the ISR should be re-entrant. If the called function is not re-entrant, it can cause issues.
For example, if the function is not re-entrant and is also called from another part of the code (outside the ISR), a problem arises if the ISR interrupts and tries to call the same function while it’s already in use. This can lead to race conditions, data corruption, or unexpected behavior.
Q) What is a nested interrupt?
In a nested interrupt system, an interrupt is allowed any time and anywhere even an ISR is executed. But, only the highest priority ISR will be executed immediately. The second-highest priority ISR will be executed after the highest one is completed.
The rules of a nested interrupt system are:
- All interrupts must be prioritized.
- After initialization, any interrupts are allowed to occur anytime and anywhere.
- If a low-priority ISR is interrupted by a high-priority interrupt, the high-priority ISR is executed.
- If a high-priority ISR is interrupted by a low-priority interrupt, the high-priority ISR continues executing.
- The same priority ISRs must be executed by time order

Q) What is NVIC in ARM Cortex?
The Nested Vector Interrupt Controller (NVIC) in the Cortex-M processor family is an example of an interrupt controller with extremely flexible interrupt priority management. It enables programmable priority levels, automatic nested interrupt support, along with support for multiple interrupt masking, whilst still being very easy to use by the programmer.
The Cortex-M3 and Cortex-M4 processors the NVIC supports up to 240 interrupt inputs, with 8 up to 256 programmable priority levels

Q) Can we change the interrupt priority level of the Cortex-M processor family?
Yes, we can.
Q) Explain Interrupts tail-chaining – ARM?
Tail-chaining is the back-to-back processing of exceptions without the overhead of state saving and restoration between interrupts. That means handling the pending interrupts without repeating the stacking. The processor tail-chains if a pending interrupt has higher priority than all stacked exceptions. For more detail, you can read Cortex-Manual.
Q) When to use Polling or Interrupt based method in embedded system?
Which method we should use; it totally depends on the specific requirements of embedded system, embedded system constraints, and system resources and complexity. Here I try to explain some of the situation where you should prefer interrupt method beside the polling.
- If events occur Infrequent or asynchronous in nature or urgent then, an interrupt-based handler would make more sense.
- If require high responsive handling without wasting the CPU cycle then, an interrupt-based handler would be good choice. For an example, if you want to implement a pulse counter on digital input then interrupt method would be good choice.
Q) What is segmentation fault?
A segmentation fault, also called a segfault, is a common runtime error that causes programs to crash. It occurs when a program tries to access an area of memory that it is not allowed to access. In operating systems, a core dump file is often created during a segmentation fault, which developers can use to debug and identify the root cause of the crash.
Q) What are the common causes of segmentation fault in C?
There are many reasons for the segmentation fault, here I am listing some common causes of the segmentation fault.
- Dereferencing a NULL pointer.
- Tried to write read-only memory (such as code segment).
- Trying to access a nonexistent memory address (outside process’s address space).
- Trying to access memory the program does not have rights to (such as kernel structures in process context).
- Sometimes dereferencing or assigning to an uninitialized pointer (because might point an invalid memory) can be the cause of the segmentation fault.
- Dereferencing the freed memory (after calling the free function) can also be caused by the segmentation fault.
- A stack overflow is also caused by the segmentation fault.
- A buffer overflow (try to access the array beyond the boundary) is also a cause of the segmentation fault.
Q) How to Avoid Segmentation Faults in C?
You should follow the following steps to avoid the segmentation fault: –
- Initialize Pointers Properly.
- Check Pointer Values Before Dereferencing.
- Avoid Buffer Overflows.
- Check Array boundary before accessing the array.
- Free the dynamically Allocated Memory Safely.
- Avoid Stack Overflow scenario.
Q) What is the difference between Segmentation fault and Bus error?
In the case of segmentation fault, SIGSEGV (11) signal is generated. Generally, a segmentation fault occurs when the program tries to access the memory to which it doesn’t have access to.
In below I have mentioned some scenarios where SIGSEGV signal is generated.
- When trying to de-referencing a NULL pointer.
- Trying to access memory which is already de-allocated (trying to use dangling pointers).
- Using uninitialized pointer(wild pointer).
- Trying to access memory that the program doesn’t own (eg. trying to access an array element out of array bounds).
In case of a BUS error, SIGBUS (10) signal is generated. The Bus error issue occurs when a program tries to access an invalid memory or unaligned memory. The bus error comes rarely as compared to the segmentation fault.
In below I have mentioned some scenarios where SIGBUS signal is generated.
- Non-existent address.
- Unaligned access.
- Paging errors
Q) What are the start-up code steps?
Start-up code for C programs usually consists of the following actions, performed in the order described:
- Disable all interrupts: Ensure that no interrupts interfere during system initialization.
- Copy initialized data from ROM to RAM.
- Zero the uninitialized data area: Clear the BSS section (uninitialized global/static variables) by setting it to zero.
- Allocate space for and initialize the stack: Set up the stack space and stack pointer.
- Initialize the processor’s stack pointer: Set the stack pointer to its start location.
- If dynamic memory allocation is used, set up the heap memory.
- Enable interrupts: Re-enable interrupts after initialization.
- Call main function: Jump to the main() function to start the user application.
Q) Why is the “C” language mostly preferred over assembly language?
C helps programmers focus on the structure of the code rather than the low-level demands of the CPU. They can organize code into components, such as functions and files and they have ways of managing the complexity of a project; without thinking about the nitty-gritty of issues such as how function calls work.
Since C is a portable language, code can be organized into general-purpose libraries that can be used on any platform, often with no modification. It is a great weapon against ‘reinventing the wheel.
Q) Can we have a volatile pointer?
Yes, we can create a volatile pointer in C language.
// piData is a volatile pointer to an integer. int * volatile piData;
Q) The Proper place to use the volatile keyword?
A volatile is an important qualifier in C programming. Here I am pointing some places where we need to use the volatile keyword.
- Accessing the memory-mapped peripherals register or hardware status register.
#define COM_STATUS_BIT 0x00000006
uint32_t const volatile * const pStatusReg = (uint32_t*)0x00020000;
unit32_t GetRecvData()
{
unit32_t RecvData;
//Code to receive data
while (((*pStatusReg) & COM_STATUS_BIT) == 0)
{
// Wait until flag does not set
//Received data in RecvData
}
return RecvData;
}
- Sharing the global variables or buffers between the multiple threads.
- Accessing the global variables in an interrupt routine or signal handler.
volatile int giFlag = 0;
ISR(void)
{
giFlag = 1;
}
int main(void)
{
while (!giFlag)
{
//do some work
}
return 0;
}
Q) Infinite loops often arise in embedded systems. How do you code an infinite loop in C?
In embedded systems, infinite loops are generally used. If I talked about a small program to control a led through the switch, in that scenario an infinite loop will be required if we are not going through the interrupt.
There are different ways to create an infinite loop, here I am mentioning some methods.
Method 1:
while(1)
{
// task
}
Method 2:
for(;;)
{
// task
}
Method 3:
Loop: goto Loop;
Q) How to access the fixed memory location in embedded C?
Let us see an example code to understand this concept. This question is one of the best questions of the embedded C interview question.
Suppose in an application, you need to access a fixed memory address. So you need to follow the below steps, these are high-level steps.
//Memory address, you want to access #define RW_FLAG 0x1FFF7800 //Pointer to access the Memory address volatile uint32_t *flagAddress = NULL; //variable to stored the read value uint32_t readData = 0; //Assign addres to the pointer flagAddress = (volatile uint32_t *)RW_FLAG; //Read value from memory * flagAddress = 12; // Write //Write value to the memory readData = * flagAddress;
Q) Difference between RISC and CISC processor?
The RISC (reduced instruction set computer) and CISC (Complex instruction set computer) are the processors ISA (instruction set architecture).
There are the following difference between both architecture:
| RISC | CISC | |
| Acronym | It stands for ‘Reduced Instruction Set Computer’. | It stands for ‘Complex Instruction Set Computer’. |
| Definition | The RISC processors have a smaller set of instructions with few addressing nodes. | The CISC processors have a larger set of instructions with many addressing nodes. |
| Memory unit | It has no memory unit and uses a separate hardware to implement instructions. | It has a memory unit to implement complex instructions. |
| Program | It has a hard-wired unit of programming. | It has a micro-programming unit. |
| Design | It is a complex complier design. | It is an easy complier design. |
| Calculations | The calculations are faster and precise. | The calculations are slow and precise. |
| Decoding | Decoding of instructions is simple. | Decoding of instructions is complex. |
| Time | Execution time is very less. | Execution time is very high. |
| External memory | It does not require external memory for calculations. | It requires external memory for calculations. |
| Pipelining | Pipelining does function correctly. | Pipelining does not function correctly. |
| Stalling | Stalling is mostly reduced in processors. | The processors often stall. |
| Code expansion | Code expansion can be a problem. | Code expansion is not a problem. |
| Disc space | The space is saved. | The space is wasted. |
| Applications | Used in high-end applications such as video processing, telecommunications and image processing. | Used in low-end applications such as security systems, home automations, etc. |
Images Courtesy: ics.uci.edu
Q) What is the stack overflow?
If your program tries to access beyond the limit of the available stack memory, then stack overflow occurs. In other words, you can say that a stack overflow occurs if the call stack pointer exceeds the stack boundary.
If stack overflow occurs, the program can crash or you can say that segmentation fault that is the result of the stack overflow.
Q) Why must the GPIO clock be enabled before configuring GPIO?
Because the GPIO peripheral’s internal registers and control logic require a clock to process bus transactions and update their state.
Q) Does disabling the GPIO clock reset the registers?
No. Clock gating stops the peripheral’s operation but generally does not reset its configuration.
Q) Why does clock gating reduce power?
Clock gating eliminates unnecessary switching activity inside digital logic, significantly reducing dynamic power consumption.
Q) What is the difference between clock gating and peripheral reset?
Clock gating stops the peripheral clock while preserving configuration. A peripheral reset clears registers and returns the peripheral to its default state.
Q) What is the cause of the stack overflow?
In the embedded application we have a little amount of stack memory as compare to the desktop application. So we have to work on embedded application very carefully either we can face the stack overflow issues that can be a cause of the application crash.
Here, I have mentioned some causes of unwanted use of the stack.
- Improper use of the recursive function.
- Passing to many arguments in the function.
- Passing a structure directly into a function.
- Nested function calls.
- Creating a huge size local array.
Q) What is the difference between the I2c and SPI communication Protocols?
In the embedded system, I2C and SPI both play an important role. Both communication protocols are the example of synchronous communication but still, both have some important differences.
The important difference between the I2C and SPI communication protocol.
- I2C supports half-duplex while SPI is full-duplex communication.
- I2C requires only two-wire for communication while SPI requires three or four-wire for communication (depends on requirement).
- I2C is slower as compared to the SPI communication.
- I2C draws more power than SPI.
- I2C is less susceptible to noise than SPI.
- I2C is cheaper to implement than the SPI communication protocol.
- I2C work on wire and logic and it has a pull-up resistor while there is no requirement of a pull-up resistor in case of the SPI.
- In I2C communication we get the acknowledgment bit after each byte, it is not supported by the SPI communication protocol.
- I2C ensures that data sent is received by the slave device while SPI does not verify that data is received correctly.
- I2C supports multi-master communication while multi-master communication is not supported by the SPI.
- One great difference between I2C and SPI is that I2C supports multiple devices on the same bus without any additional select lines (work based on device address) while SPI requires additional signal (slave select lines) lines to manage multiple devices on the same bus.
- I2C supports arbitration while SPI does not support the arbitration.
- I2C support the clock stretching while SPI does not support the clock stretching.
- I2C can be locked up by one device that fails to release the communication bus.
- I2C has some extra overhead due to start and stop bits.
- I2C is better for long-distance while SPI is better for the short distance.
- In the last I2C developed by NXP while SPI by Motorola.
Q) What is the difference between Asynchronous and Synchronous Communication?
There are the following differences between asynchronous and synchronous communication.
| Asynchronous Communication | Synchronous Communication |
| There is no common clock signal between the sender and receivers. | Communication is done by a shared clock. |
| Sends 1 byte or character at a time. | Sends data in the form of blocks or frames. |
| Slow as compare to synchronous communication. | Fast as compare to asynchronous communication. |
| Overhead due to start and stop bit. | Less overhead. |
| Ability to communicate long distance. | Less as compared to asynchronous communication. |
| A start and stop bit used for data synchronization. | A shared clock is used for data synchronization. |
| Economical | Costly |
| RS232, RS485 | I2C, SPI. |
Q) What is the difference between RS232 and RS485?
The RS232 and RS485 is an old serial interface. Both serial interfaces are the standard for data communication. This question is also very important and generally ask by an interviewer.
Some important difference between the RS232 and RS485
| Parameter | RS232 | RS485 |
| Line configuration | Single –ended | differential |
| Numbers of devices | 1 transmitter 1 receiver | 32 transmitters 32 receivers |
| Mode of operation | Simplex or full duplex | Simplex or half duplex |
| Maximum cable length | 50 feet | 4000 feet |
| Maximum data rate | 20 Kbits/s | 10 Mbits/s |
| signaling | unbalanced | balanced |
| Typical logic levels | +-5 ~ +-15V | +-1.5 ~ +-6V |
| Minimum receiver input impedance | 3 ~ 7 K-ohm | 12 K-ohm |
| Receiver sensitivity | +-3V | +-200mV |
Q) What is the difference between Bit Rate and Baud Rate?
| Bit Rate | Baud Rate |
| Bit rate is the number of bits per second. | Baud rate is the number of signal units per second. |
| It determines the number of bits traveled per second. | It determines how many times the state of a signal is changing. |
| Cannot determine the bandwidth. | It can determine how much bandwidth is required to send the signal. |
| This term generally used to describe the processor efficiency. | This term generally used to describe the data transmission over the channel. |
| Bit rate = baud rate x the number of bits per signal unit | Baud rate = bit rate / the number of bits per signal unit |
Q) Size of the integer depends on what?
The C standard is explained that the minimum size of the integer should be 16 bits. Some programing language is explained that the size of the integer is implementation-dependent but portable programs shouldn’t depend on it.
Primarily the size of integer depends on the type of the compiler which has written by compiler writer for the underlying processor. You can see compilers merrily changing the size of integer according to convenience and underlying architectures. So it is my recommendation to use the C99 integer data types ( uin8_t, uin16_t, uin32_t ..) in place of standard int.
Q) Are integers signed or unsigned?
According to the C standard, an integer data type is by default signed. So if you create an integer variable, it can store both positive and negative values.
For more details on signed and unsigned integers, check out:
A closer look at signed and unsigned integers in C
Q) What is a difference between unsigned int and signed int in C?
The signed and unsigned integer type has the same storage (according to the standard at least 16 bits) and alignment but still, there is a lot of difference them, in bellows lines, I am describing some difference between the signed and unsigned integer.
- A signed integer can store the positive and negative value both but beside it unsigned integer can only store the positive value.
- The range of nonnegative values of a signed integer type is a sub-range of the corresponding unsigned integer type.
For example,
Assuming the size of the integer is 2 bytes.
signed int -32768 to +32767
unsigned int 0 to 65535 - When computing the unsigned integer, it never gets overflow because if the computation result is greater than the largest value of the unsigned integer type, it is reduced modulo the number that is one greater than the largest value that can be represented by the resulting type.
For example,
Computational Result % (Largest value of the unsigned integer+1) - The overflow of the signed integer type is undefined.
- If Data is signed type negative value, the right shifting operation of Data is implementation-dependent but for the unsigned type, it would be Data/ 2pos.
- If Data is signed type negative value, the left shifting operation of Data shows the undefined behavior but for the unsigned type, it would be Data x 2pos.
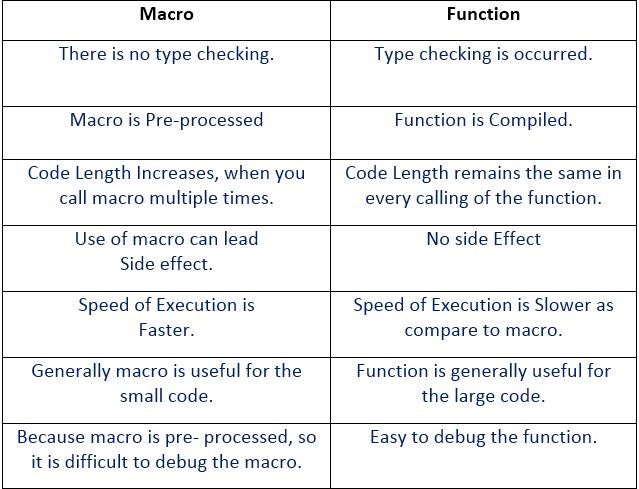
Q) What is the difference between a macro and a function?
Q) What is the difference between typedef & Macros?
Let’s see the short description of the typedef and macro to understand the difference between them.
typedef:
The C language provides a very important keyword typedef for defining a new name for existing types. The typedef is the compiler directive mainly use with user-defined data types (structure, union or enum) to reduce their complexity and increase code readability and portability.
Syntax,
typedef type NewTypeName;
Let’s take an example,
typedef unsigned int UnsignedInt;
Now UnsignedInt is a new type and using it, we can create a variable of unsigned int. So in the below example, Mydata is unsigned int variable.
UnsignedInt Mydata;
Note: A typedef creates synonyms or a new name for existing types it does not create new types.
Macro:
A macro is a pre-processor directive and it replaces the value before compiling the code. One of the major problems with the macro is that there is no type checking. Generally, the macro is used to create the alias, in C language. A macro is also used as a file guard in C and C++.
Syntax,
#define MACRO_NAME MACRO_VALUE
Let’s take an example,
#define VALUE 10
Now VALUE becomes 10 in your program. You can use the VALUE in place of the 10.
For more details, you can see below-mentioned articles,
Q) What do you mean by enumeration in C?
An enum in C is a user-defined data type. It consists set of named constant integers. Using the enum keyword, we can declare an enumeration type by using the enumeration tag (optional) and a list of named integer.
Basically, we used the enum to increase the code readability and with enum easy to debug the code as compared to symbolic constant (macro). The most important property of enum is that it follows the scope rule and the compiler automatically assigns the value to its member constant.
Note: A variable of enumeration type stores one of the values of the enumeration list defined by that type.
Syntax of enum,
enum Enumeration_Tag { Enumeration_List };
The Enumeration_Tag specifies the enumeration type name.
The Enumeration_List is a comma-separated list of named constant.
Example,
enum FLASH_ERROR { DEFRAGMENT_ERROR, BUS_ERROR};
For more details, you can see below-mentioned articles,
Q) What is the difference between const and macro?
- The const keyword is handled by the compiler, in another hand, a macro is handled by the preprocessor directive.
- const is a qualifier that is modified the behavior of the identifier but macro is preprocessor directive.
- There is type checking is occurred with const keyword but does not occur with #define.
- const is scoped by C block, #define applies to a file.
- const can be passed as a parameter (as a pointer) to the function. In the case of call by reference, it prevents to modify the passed object value.
Q) How to set, clear, toggle and checking a single bit in C?
Note: Here I assume that bit of register starts with 0th position, it means the 2nd position is actually 3rd bits.
| D7 | D6 | D5 | D4 | D3 | D2 | D1 | D0 |
Setting N-th Bit
Setting an N-th bit means that if the N-th bit is 0, then set it to 1 and if it is 1 then leave it unchanged. In C, bitwise OR operator (|) use to set a bit of integral data type. As we know that | (Bitwise OR operator) evaluates a new integral value in which each bit position is 1 only when operand’s (integer type) has a 1 in that position.
In simple words, you can say that “Bitwise OR ” of two bits is always one if any one of them is one.
That means, 0 | 0 = 0 1 | 0 = 1 0 | 1 = 1 1 | 1 = 1
Algorithm to set the bits:
Number | = (1UL << nth Position);
Clearing a Bit
Clearing a bit means that if N-th bit is 1, then clear it to 0 and if it is 0 then leave it unchanged. Bitwise AND operator (&) use to clear a bit of integral data type. “AND” of two bits is always zero if any one of them is zero.
That means, 0 & 0 = 0 1 & 0 = 0 0 & 1 = 0 1 & 1 = 1
Algorithm to clear the bit:
To clear the nth bit, first, you need to invert the string of bits then AND it with the number.
Number &= ~(1UL << nth Position);
Checking a Bit
To check the nth bit, shift the ‘1’ nth position toward the left and then “AND” it with the number.
An algorithm to check the bit
Bit = Number & (1UL << nth);
Toggling a Bit
Toggling a bit means that if the N-th bit is 1, then change it to 0 and if it is 0 then change it to 1. Bitwise XOR (^) operator use to toggle the bit of an integral data type. To toggle the nth bit shift the ‘1’ nth position toward the left and “XOR” it.
That means, 0 ^ 0 = 0 1 ^ 0 = 1 0 ^ 1 = 1 1 ^ 1 = 0
An algorithm to toggle the bits
Number ^= (1UL << nth Position);
You can see the below Articles,
Q) What will be the output of the below C program?
#include <stdio.h>
int main()
{
char var = 10;
void *ptr = &var;
printf("%d %d",*(char*)ptr,++(*(char*)ptr));
return 0;
}
Output: undefined
Explanation: Due to the sequence point the output vary on a different platform.
Q) Write a program swap two numbers without using the third variable?
Let’s assume a, b two numbers, there are a lot of methods two swap two numbers without using the third variable.
Method 1( (Using Arithmetic Operators):
#include <stdio.h>
int main()
{
int a = 10, b = 5;
// algo to swap 'a' and 'b'
a = a + b; // a becomes 15
b = a - b; // b becomes 10
a = a - b; // fonally a becomes 5
printf("After Swapping the value of: a = %d, b = %d\n\n", a, b);
return 0;
}
Method 2 (Using Bitwise XOR Operator):
#include <stdio.h>
int main()
{
int a = 10, b = 5;
// algo to swap 'a' and 'b'
a = a ^ b; // a becomes (a ^ b)
b = a ^ b; // b = (a ^ b ^ b), b becomes a
a = a ^ b; // a = (a ^ b ^ a), a becomes b
printf("After Swapping the value of: a = %d, b = %d\n\n", a, b);
return 0;
}
Q) What will be the output of the below C program?
#include <stdio.h>
#define ATICLEWORLD 0x01
#define AUTHOR 0x02
int main()
{
unsigned char test = 0x00;
test|=ATICLEWORLD;
test|=AUTHOR;
if(test & ATICLEWORLD)
{
printf("I am an Aticleworld");
}
if( test & AUTHOR)
{
printf(" Author");
}
return 0;
}
Output: I am an Aticleworld Author
Explanation:When we are OR-ing the test( unsigned char variable) with 0x01 and 0x02. The value of test will be 0x03 (because initially test value is 0x00). When we perform the And-ing operatotion on test with 0x01 and 0x02 then expresstion will return non-zero value, for example (0x00000011 & 0x00000001 => 0x00000010).
Q) What is meant by structure padding?
In the case of structure or union, the compiler inserts some extra bytes between the members of structure or union for the alignment, these extra unused bytes are called padding bytes and this technique is called padding.
Padding has increased the performance of the processor at the penalty of memory. In structure or union data members aligned as per the size of the highest bytes member to prevent the penalty of performance.
Note: Alignment of data types mandated by the processor architecture, not by language.
You can see the below Articles,
Q) What is the endianness?
The endianness is the order of bytes to store data in memory and it also describes the order of byte transmission over a digital link. In the memory data store in which order depends on the endianness of the system, if the system is big-endian then the MSB byte store first (means at lower address) and if the system is little-endian then LSB byte store first (means at lower address).
Some examples of the little-endian and big-endian system.

Q) What is big-endian and little-endian?
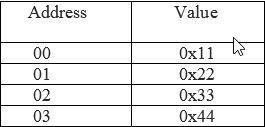
Suppose, 32 bits Data is 0x11223344.

Big-endian
The most significant byte of data stored at the lowest memory address.
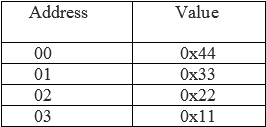
Little-endian
The least significant byte of data stored at the lowest memory address.
Note: Some processor has the ability to switch one endianness to other endianness using the software means it can perform like both big-endian or little-endian at a time. This processor is known as the Bi-endian, here are some architecture (ARM version 3 and above, Alpha, SPARC) who provide the switchable endianness feature.
Q) Write a C program to check the endianness of the system.
Method 1:
#include <stdio.h>
#include <stdlib.h>
#include <inttypes.h>
int main(void)
{
uint32_t u32RawData;
uint8_t *pu8CheckData;
u32RawData = 0x11223344; //Assign data
pu8CheckData = (uint8_t *)&u32RawData; //Type cast
if (*pu8CheckData == 0x44) //check the value of lower address
{
printf("little-Endian");
}
else if (*pu8CheckData == 0x11) //check the value of lower address
{
printf("big-Endian");
}
return 0;
}
Method 2:
#include <stdio.h>
#include <stdlib.h>
#include <inttypes.h>
typedef union
{
uint32_t u32RawData; // integer variable
uint8_t au8DataBuff[4]; //array of character
} RawData;
int main(void)
{
RawData uCheckEndianess;
uCheckEndianess.u32RawData = 0x11223344; //assign the value
if (uCheckEndianess.au8DataBuff[0] == 0x44) //check the array first index value
{
printf("little-endian");
}
else if (uCheckEndianess.au8DataBuff[0] == 0x11) //check the array first index value
{
printf("big-endian");
}
return 0;
}
Q) How to Convert little-endian to big-endian vice versa in C?
We can convert little-endian to big-endian or vice versa using the C programs. So let us see few ways to convert one endian to another.
#include <stdio.h>
#include <inttypes.h>
//Function to change one endian to another
uint32_t ChangeEndianness(uint32_t u32Value)
{
uint32_t u32Result = 0;
u32Result |= (u32Value & 0x000000FF) << 24;
u32Result |= (u32Value & 0x0000FF00) << 8;
u32Result |= (u32Value & 0x00FF0000) >> 8;
u32Result |= (u32Value & 0xFF000000) >> 24;
return u32Result;
}
int main()
{
uint32_t u32CheckData = 0x11223344;
uint32_t u32ResultData =0;
//swap the data
u32ResultData = ChangeEndianness(u32CheckData);
//converted data
printf("0x%x\n",u32ResultData);
return 0;
}
Output:
0x44332211
For more detail, you can see Article,
Q) What is static memory allocation and dynamic memory allocation?
According to C standard, there are four storage duration, static, thread (C11), automatic, and allocated. The storage duration determines the lifetime of the object.
The static memory allocation:
Static Allocation means, an object has an external or internal linkage or declared with static storage-class. It’s initialized only once, before program startup and its lifetime is throughout the execution of the program. A global and static variable is an example of static memory allocation.
The dynamic memory allocation:
In C language, there are a lot of library functions (malloc, calloc, or realloc,..) which are used to allocate memory dynamically. One of the problems with dynamically allocated memory is that it is not destroyed by the compiler itself that means it is the responsibility of the user to deallocate the allocated memory.
When we allocate the memory using the memory management function, they return a pointer to the allocated memory block and the returned pointer is pointing to the beginning address of the memory block. If there is no space available, these functions return a null pointer.
Q) What is the memory leak in C?
A memory leak is a common and dangerous problem. It is a type of resource leak. In C language, a memory leak occurs when you allocate a block of memory using the memory management function and forget to release it.
int main ()
{
char * pBuffer = malloc(sizeof(char) * 20);
/* Do some work */
return 0; /*Not freeing the allocated memory*/
}
Note: once you allocate a memory than allocated memory does not allocate to another program or process until it gets free.
Q) What is the output of the below C code?
#include <stdio.h>
int main(void)
{
int var;
for(var = -3 ; var <sizeof(int) ; var++)
{
printf("Hello Aticleworld\n");
}
return 0;
}
Output:
Nothing will print.
Explanation: In the above C code, We are trying to compare a signed int variable “var” with size_t, which is defined as an unsigned long int (sizeof operator return size_t). Here integer promotion occurs and the compiler will convert signed int -3 to unsigned long int and resultant value would very large as compare to int size. So the for loop condition will be false and there won’t be any iteration.
Q) What is the output of the below C code?
#include <stdio.h>
int main()
{
int pos = 14;
float data = 15.2;
printf("%*f",pos,data);
return 0;
}
Output:
print 15.200000 with 6 spaces.
Explanation: The output will be ______15.20000, where _ has been used to represent space here. The program will print a floating-point number with a width of at least 14 and since no precision has been specified, it will take the default precision of 6 decimal point for format specifier “f”.
The symbol * can be used with a format specifier to replace the width or precision. Here it has been used to replace the width. The general format for %f can be seen as %(width). (precision)f. When * is used to specify width or precision. Let see a C code for the same.
#include <stdio.h>
int main()
{
int pos = 14;
float data = 15.2;
printf("%*.*f",pos,2,data);
return 0;
}
Output:
print 15.20 with spaces.
Q) What is the difference between malloc and calloc?
A malloc and calloc are memory management functions. They are used to allocate memory dynamically. Basically, there is no actual difference between calloc and malloc except that the memory that is allocated by calloc is initialized with 0.
In C language,calloc function initialize the all allocated space bits with zero but malloc does not initialize the allocated memory. These both function also has a difference regarding their number of arguments, malloc takes one argument but calloc takes two.
Q) What is the purpose of realloc( )?
The realloc function is used to resize the allocated block of memory. It takes two arguments first one is a pointer to previously allocated memory and the second one is the newly requested size.
The calloc function first deallocates the old object and allocates again with the newly specified size. If the new size is lesser to the old size, the contents of the newly allocated memory will be the same as prior but if any bytes in the newly created object goes beyond the old size, the values of the exceeded size will be indeterminate.
Syntax:
void *realloc(void *ptr, size_t size);
Let’s see an example to understand the working of realloc in C language.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main ()
{
char *pcBuffer = NULL;
/* Initial memory allocation */
pcBuffer = malloc(8);
//make sure piBuffer is valid or not
if (pcBuffer == NULL)
{
// allocation failed, exit from the program
fprintf(stderr, "Out of memory!\n");
exit(1);
}
strcpy(pcBuffer, "aticle");
printf("pcBuffer = %s\n", pcBuffer);
/* Reallocating memory */
pcBuffer = realloc(pcBuffer, 15);
if (pcBuffer == NULL)
{
// allocation failed, exit from the program
fprintf(stderr, "Out of memory!\n");
exit(1);
}
strcat(pcBuffer, "world");
printf("pcBuffer = %s\n", pcBuffer);
//free the allocated memory
free(pcBuffer);
return 0;
}
Output:
pcBuffer = aticle
pcBuffer = aticleworld
Note: It should be used for dynamically allocated memory but if a pointer is a null pointer, realloc behaves like the malloc function.
Q) What is the return value of malloc (0)?
If the size of the requested space is zero, the behavior will be implementation-defined. The return value of the malloc could be a null pointer or it shows the behavior of that size is some nonzero value. It is suggested by the standard to not use the pointer to access an object that is returned by the malloc while the size is zero.
Q) What is dynamic memory fragmentation?
The memory management function is guaranteed that if memory is allocated, then it would be suitably aligned to any object which has the fundamental alignment. The fundamental alignment is less than or equal to the largest alignment that’s supported by the implementation without an alignment specification.
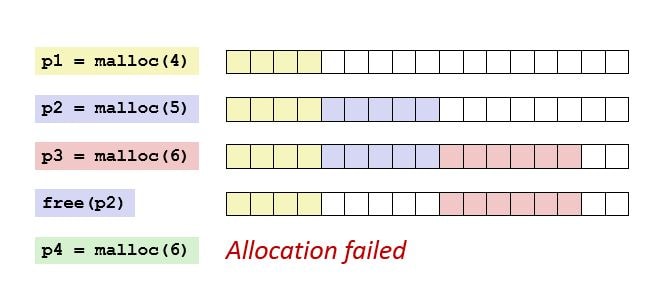
One of the major problems with dynamic memory allocation is fragmentation, basically, fragmentation occurred when the user does not use the memory efficiently. There are two types of fragmentation, external fragmentation, and internal fragmentation.
The external fragmentation is due to the small free blocks of memory (small memory hole) that is available on the free list but the program not able to use it. There are different types of free list allocation algorithms that used the free memory block efficiently.
To understand the external fragmentation, consider a scenario where a program has 3 contiguous blocks of memory and the user frees the middle block of memory. In that scenario, you will not get a memory, if the required block of memory is larger than a single block of memory (but smaller or equal to the aggregate of the block of memory).
The internal fragmentation is wasted of memory that is allocated for rounding up the allocated memory and in bookkeeping (infrastructure), the bookkeeping is used to keep the information of the allocated memory.
Whenever we called the malloc function then it reserves some extra bytes (depend on implementation and system) for bookkeeping. This extra byte is reserved for each call of malloc and becomes a cause of the internal fragmentation.
For example,
See the below code, the programmer may think that the system will be allocated 8 *100 (800) bytes of memory but due to bookkeeping (if 8 bytes) system will be allocated 8*100 extra bytes. This is an internal fragmentation, where 50% of the heap waste.
char *acBuffer[100];
int main()
{
int iLoop = 0;
while(iLoop < 100)
{
acBuffer[iLoop ] = malloc(8);
++iLoop;
}
}
Q) How is the free work in C?
When we call the memory management functions (malloc, calloc or realloc) then these functions keep extra bytes for bookkeeping. Whenever we call the free function and pass the pointer that is pointing to allocated memory, the free function gets the bookkeeping information and release the allocated memory. Anyhow if you or your program change the value of the pointer that is pointing to the allocated address, the calling of the free function gives the undefined result.
____ The allocated block ____
/ \
+--------+--------------------+
| Header | Your data area ... |
+--------+--------------------+
^
|
+-- Returned Address
Let us see a program to understand the above concept. The behavior of the below program is not defined.
#include <stdio.h>
#include <stdlib.h>
int main()
{
char *pcBuffer = NULL;
//Allocate the memory
pcBuffer = malloc(sizeof(char) * 16);
//make sure piBuffer is valid or not
if (pcBuffer == NULL)
{
// allocation failed, exit from the program
fprintf(stderr, "Out of memory!\n");
exit(1);
}
//Increment the pointer
pcBuffer++;
//Call free function to release the allocated memory
free(pcBuffer);
return 0;
}
OutPut: Undefined Result
Q) What is a Function Pointer?
A function pointer is similar to the other pointers but the only difference is that it points to a function instead of a variable. In another word, we can say that a function pointer is a type of pointer that store the address of a function and these pointed function can be invoked by function pointer in a program whenever required.
Q) How to declare a pointer to a function in C?
The syntax for declaring function pointer is very straightforward. It seems difficult in beginning but once you are familiar with function pointer then it becomes easy.
The declaration of a pointer to a function is similar to the declaration of a function. That means the function pointer also requires a return type, declaration name, and argument list. One thing that you need to remember here is, whenever you declare the function pointer in the program then the declaration name is preceded by the * (Asterisk) symbol and enclosed in parenthesis.
For example,
void ( *fpData )( int );
For a better understanding, let’s take an example to describe the declaration of a function pointer in the C program.
e.g,
void ( *pfDisplayMessage) (const char *);
In the above expression, pfDisplayMessage is a pointer to a function taking one argument, const char *, and returns void.
When we declare a pointer to function in c then there is a lot of importance of the bracket. If in the above example, I remove the bracket, then the meaning of the above expression will be change and it becomes void *pfDisplayMessage (const char *). It is a declaration of a function that takes the const character pointer as arguments and returns a void pointer.
Q) Where can the function pointers be used?
There are a lot of places, where the function pointers can be used. Generally, function pointers are used in the implementation of the callback function, finite state machine and to provide the feature of polymorphism in C language …etc.
Q) Write a program to check an integer is a power of 2?
Here, I am writing a small algorithm to check the power of 2. If a number is a power of 2, function return 1.
int CheckPowerOftwo (unsigned int x)
{
return ((x != 0) && !(x & (x - 1)));
}
Q) What is the output of the below code?
#include <stdio.h>
int main()
{
int x = -15;
x = x << 1;
printf("%d\n", x);
}
Output:
undefined behavior.
Q) What is the output of the below code?
#include <stdio.h>
int main()
{
int x = -30;
x = x >> 1;
printf("%d\n", x);
}
Output:
implementation-defined.
Q) Write a program to count set bits in an integer?
unsigned int NumberSetBits(unsigned int n)
{
unsigned int CountSetBits= 0;
while (n)
{
CountSetBits += n & 1;
n >>= 1;
}
return CountSetBits;
}
Q) What is void or generic pointers in C?
A void pointer in c is called a generic pointer, it has no associated data type. It can store the address of any type of object and it can be type-casted to any type. According to C standard, the pointer to void shall have the same representation and alignment requirements as a pointer to a character type. A void pointer declaration is similar to the normal pointer, but the difference is that instead of data types we use the void keyword.
Syntax:
void * Pointer_Name;
You can check these articles,
Q) What is the advantage of a void pointer in C?
There are following advantages of a void pointer in c.
- Using the void pointer we can create a generic function that can take arguments of any data type. The memcpy and memmove library function are the best examples of the generic function, using these functions we can copy the data from the source to destination.
- We know that void pointer can be converted to another data type that is the reason malloc, calloc or realloc library function return void *. Due to the void * these functions are used to allocate memory to any data type.
- Using the void * we can create a generic linked list. For more information see this link: How to create generic Link List.
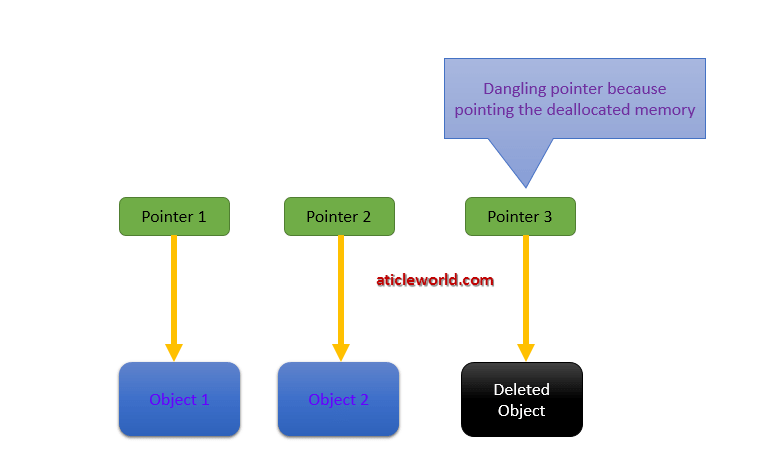
Q) What are dangling pointers?
Generally, daggling pointers arise when the referencing object is deleted or deallocated, without changing the value of the pointers. It creates the problem because the pointer is still pointing the memory that is not available. When the user tries to dereference the daggling pointers than it shows the undefined behavior and can be the cause of the segmentation fault.
For example,
#include<stdio.h>
#include<stdlib.h>
int main()
{
int *piData = NULL;
//creating integer of size 10.
piData = malloc(sizeof(int)* 10);
//make sure piBuffer is valid or not
if (piData == NULL)
{
// allocation failed, exit from the program
fprintf(stderr, "Out of memory!\n");
exit(1);
}
//free the allocated memory
free(piData);
//piData is dangling pointer
*piData = 10;
printf("%d",*piData);
return 0;
}
OutPut: Undefined Result
In simple words, we can say that a dangling pointer is a pointer that is not pointing to valid memory. So if we access these pointers then the behaviour of the program will undefine.
Q) What is the wild pointer?
A pointer that is not initialized properly before its first use is known as the wild pointer. Uninitialized pointer’s behavior is totally undefined because it may point some arbitrary location that can be the cause of the program crash, that’s is the reason it is called a wild pointer.
In other words, we can say every pointer in programming languages that are not initialized either by the compiler or programmer begins as a wild pointer.
Note: Generally, compilers warn about the wild pointer.
Syntax,
int *piData; //piData is wild pointer.
Q) What is a NULL pointer?
According to C standard, an integer constant expression with the value 0, or such an expression cast to type void *, is called a null pointer constant. If a null pointer constant is converted to a pointer type, the resulting pointer, called a null pointer.
Syntax,
int *piData = NULL; // piData is a null pointer
Q) What are the post-increment and decrement operators?
When we use a post-increment (++) operator on an operand then the result is the value of the operand and after getting the result, the value of the operand is incremented by 1. The working of the post-decrement (–) operator is similar to the post-increment operator but the difference is that the value of the operand is decremented by 1.
Note: incrementation and decrementation by 1 are the types specified.
Q) Which one is better: Pre-increment or Post increment?
Nowadays compiler is enough smart, they optimize the code as per the requirements. The post and pre-increment both have their own importance we need to use them as per the requirements.
If you are reading a flash memory byte by bytes through the character pointer then here you have to use the post-increment, either you will skip the first byte of the data. Because we already know that in the case of pre-increment pointing address will be increment first and after that, you will read the value.
Let’s take an example of the better understanding,
In the below example code, I am creating a character array and using the character pointer I want to read the value of the array. But what will happen if I used a pre-increment operator? The answer to this question is that ‘A’ will be skipped and B will be printed.
#include <stdio.h>
int main(void)
{
char acData[5] = {'A','B','C','D','E'};
char *pcData = NULL;
pcData = acData;
printf("%c ",*++pcData);
return 0;
}
But in place of pre-increment if we use post-increment then the problem is getting solved and you will get A as the output.
#include <stdio.h>
int main(void)
{
char acData[5] = {'A','B','C','D','E'};
char *pcData = NULL;
pcData = acData;
printf("%c ",*pcData++);
return 0;
}
Besides that, when we need a loop or just only need to increment the operand then pre-increment is far better than post-increment because in case of post increment compiler may have created a copy of old data which takes extra time. This is not 100% true because nowadays the compiler is so smart and they are optimizing the code in a way that makes no difference between pre and post-increment. So it is my advice, if post-increment is not necessary then you have to use the pre-increment.
Note: Generally post-increment is used with array subscript and pointers to read the data, otherwise if not necessary then use pre in place of post-increment. Some compiler also mentioned that to avoid to use post-increment in looping condition.
iLoop = 0.
while (a[iLoop ++] != 0)
{
// Body statements
}
Q) Are the expressions *ptr ++ and ++*ptr same ?
Both expressions are different. Let’s see a sample code to understand the difference between both expressions.
#include <stdio.h>
int main(void)
{
int aiData[5] = {100,200,300,400,500};
int *piData = aiData;
++*piData;
printf("aiData[0] = %d, aiData[1] = %d, *piData = %d", aiData[0], aiData[1], *piData);
return 0;
}
Output: 101 , 200 , 101
Explanation:
In the above example, two operators are involved and both have the same precedence with a right to left associativity. So the above expression ++*p is equivalent to ++ (*p). In another word, we can say it is pre-increment of value and output is 101, 200, 101.
#include <stdio.h>
int main(void)
{
int aiData[5] = {100,200,30,40,50};
int *piData = aiData;
*++piData;
printf("aiData[0] = %d, aiData[1] = %d, *piData = %d", aiData[0], aiData[1], *piData);
return 0;
}
Output: 100, 200, 200
Explanation:
In the above example, two operators are involved and both have the same precedence with the right to left associativity. So the above expression *++p is equivalent to *(++p). In another word you can say it is pre-increment of address and output is 100, 200,200.
Q) What does the keyword const mean?
A const is only a qualifier, it changes the behavior of a variable and makes it read-only type. When we want to make an object read-only type, then we have to declare it as const.
Syntax,
const DataType Identifier = Value;
e.g.
const int iData = 0
At the time of declaration, const qualifier only gives the direction to the compiler that the value of declaring objects could not be changed. In simple words, const means not modifiable (cannot assign any value to the object at the runtime).
Q) How will you protect a pointer by some accidental modification with the pointer address?
With the help of the “const” keyword, we can avoid accidental modification of the pointer address.
Q) When should we use const in a C program?
There are the following places where we need to use the const keyword in the programs.
- In case of call by reference, if you don’t want to change the value of the passed variable. E.g.,
int PrintData ( const char *pcMessage);
- In some places, const is better than macro because const is handled by the compiler and has a type checking.
- In the case of the I/O and memory-mapped register, const is used with the volatile qualifier for efficient access. for eg,
const volatile uint32_t *DEVICE_STATUS = (uint32_t *) 0x80102040;
- When you don’t want to change the value of an initialized variable.
Q) What is the meaning of the below declarations?
- const int a;
- int const a;
- const int *a;
- int * const a;
- int const * a const;
- The “a” is a constant integer.
- Similar to first, “a” is a constant integer.
- Here “a” is a pointer to a const integer, the value of the integer is not modifiable, but the pointer is not modifiable.
- Here “a” is a const pointer to an integer, the value of the pointed integer is modifiable, but the pointer is not modifiable.
- Here “a” is a const pointer to a const integer that means the value of pointed integer and pointer both are not modifiable.
Q) Differentiate between a constant pointer and pointer to a constant?
Constant pointer:
A constant pointer is a pointer whose value (pointed address) is not modifiable. If you will try to modify the pointer value, you will get the compiler error.
A constant pointer is declared as follows :
Data_Type * const Pointer_Name;
Let’s see the below example code when you will compile the below code to get the compiler error.
#include<stdio.h>
int main(void)
{
int var1 = 10, var2 = 20;
//Initialize the pointer
int *const ptr = &var1;
//Try to modify the pointer value
ptr = &var2;
printf("%d\n", *ptr);
return 0;
}
Output: compiler error.
Pointer to a constant:
In this scenario the value of the pointed address is constant that means we can not change the value of the address that is pointed by the pointer.
A constant pointer is declared as follows :
Data_Type const* Pointer_Name;
Let’s take a small code to illustrate a pointer to a constant:
#include<stdio.h>
int main(void)
{
int var1 = 100;
// pointer to constant integer
const int* ptr = &var1;
//try to modify the value of pointed address
*ptr = 10;
printf("%d\n", *ptr);
return 0;
}
Output: compiler error.
Q) How to use a variable in a source file that is defined in another source file?
Using the “extern” keyword we can access a variable from one source file to another.
Q) What are the uses of the keyword static?
In C language, the static keyword has a lot of importance. If we have used the static keyword with a variable or function, then only internal or none linkage is worked. I have described some simple use of a static keyword.
- A static variable only initializes once, so a variable declared static within the body of a function maintains its prior value between function invocations.
- A global variable with a static keyword has internal linkage, so it only accesses within the translation unit (.c). It is not accessible by another translation unit. The static keyword protects your variable to access from another translation unit.
- By default in C language, the linkage of the function is external that it means it is accessible by the same or another translation unit. With the help of the static keyword, we can make the scope of the function local, it only accesses by the translation unit within it is declared.
Q) What is the difference between global and static global variables?
Global and static global variables have different linkages. It is the reason global variables can be accessed outside of the file but the static global variable only accesses within the file in which it is declared.
A static global variable ===>>> internal linkage.
A non-static global variable ===>>> external linkage.
For more details, you can see the below-mentioned articles,
Q) Differentiate between an internal static and external static variable?
In C language, the external static variable has the internal linkage and the internal static variable has no linkage. It is the reason they have a different scope but both will alive throughout the program.
A external static variable ===>>> internal linkage.
A internal static variable ===>>> none .
Q) Can static variables be declared in a header file?
Yes, we can declare the static variables in a header file.
Q) What is the difference between declaration and definition of a variable?
Declaration of a variable in C
A variable declaration only provides sureness to the compiler at the compile time that variable exists with the given type and name, so that compiler proceeds for further compilation without needing all detail of this variable. When we declare a variable in C language, we only give the information to the compiler, but there is no memory reserve for it. It is only a reference, through which we only assure the compiler that this variable may be defined within the function or outside of the function.
Note: We can declare a variable multiple times but defined only once.
eg,
extern int data; extern int foo(int, int); int fun(int, char); // extern can be omitted for function declarations
Definition of variable in C
The definition is action to allocate storage to the variable. In another word, we can say that variable definition is the way to say the compiler where and how much to create the storage for the variable generally definition and declaration occur at the same time but not almost.
eg,
int data;
int foo(int, int) { }
Note: When you define a variable then there is no need to declare it but vice versa is not applicable.
Q) What is the difference between pass by value by reference in c and pass by reference in c?
Pass By Value:
- In this method, the value of the variable is passed. Changes made to formal will not affect the actual parameters.
- Different memory locations will be created for both variables.
- Here there will be a temporary variable created in the function stack which does not affect the original variable.
Pass By Reference :
- In Pass by reference, an address of the variable is passed to a function.
- Whatever changes made to the formal parameter will affect the value of actual parameters(a variable whose address is passed).
- Both formal and actual parameters shared the same memory location.
- it is useful when you required to returns more than 1 value.
Q) What is a reentrant function?
In computing, a computer program or subroutine is called reentrant if it can be interrupted in the middle of its execution and then safely be called again (“re-entered”) before its previous invocations complete execution. The interruption could be caused by an internal action such as a jump or call, or by an external action such as an interrupt or signal. Once the reentered invocation completes, the previous invocations will resume correct execution.
Q) What are some general conditions to be reentrant?
Here are some general conditions which makes a function reentrant.
1. It should not use any static or global non-constant data without synchronization. Also shared variables should be accessed in an atomic way.
2. It does not call non-reentrant functions.
3. It may not modify itself without synchronization.
4. It does not use the hardware in a non-atomic way.
5. It would be great if it takes only pass by value parameters.
6. It may not use blocking or locking mechanisms because it may cause of deadlock situations when it called simultaneously by multiple threads or interrupts.
Q) What is the inline function?
An inline keyword is a compiler directive that only suggests the compiler substitute the function’s body at the calling the place. It is an optimization technique used by the compilers to reduce the overhead of function calls.
for example,
static inline void Swap(int *a, int *b)
{
int tmp= *a;
*a= *b;
*b = tmp;
}
Q) What is the advantage and disadvantage of the inline function?
There are a few important advantages and disadvantages of the inline function.
Advantages:-
1) It saves the function calling overhead.
2) It also saves the overhead of variables push/pop on the stack, while function calling.
3) It also saves the overhead of return call from a function.
4) It increases the locality of reference by utilizing the instruction cache.
5) After inlining compiler can also apply intraprocedural optimization if specified. This is the most important one, in this way compiler can now focus on dead code elimination, can give more stress on branch prediction, induction variable elimination, etc..
Disadvantages:-
1) May increase function size so that it may not fit in the cache, causing lots of cache miss.
2) After the inlining function, if variables numbers that are going to use register increases then they may create overhead on register variable resource utilization.
3) It may cause compilation overhead as if somebody changes code inside an inline function then all calling locations will also be compiled.
4) If used in the header file, it will make your header file size large and may also make it unreadable.
5) If somebody used too many inline functions resultant in a larger code size then it may cause thrashing in memory. More and number of page faults bringing down your program performance.
6) It’s not useful for an embedded system where a large binary size is not preferred at all due to memory size constraints.
Q) What is virtual memory?
Virtual memory is part of memory management techniques and it creates an illusion that the system has a sufficient amount of memory. In other words, you can say that virtual memory is a layer of indirection.
Q) How can you protect a character pointer by some accidental modification with the pointer address?
Using the const keyword we can protect a character pointer by some accidental modification with the pointer address. Eg, const char *ptr; here we can not change the value of the address pointed by ptr by using ptr.
Q) Consider the two statements and find the difference between them?
struct sStudentInfo
{
char Name[12];
int Age;
float Weight;
int RollNumber;
};
#define STUDENT_INFO struct sStudentInfo*
typedef struct sStudentInfo* studentInfo;
statement 1
STUDENT_INFO p1, p2;
statement 2
studentInfo q1, q2;
Both statements looking the same but actually, both are different from each other.
Statement 1 will be expanded to struct sStudentInfo * p1, p2. It means that p1 is a pointer to struct sStudentInfo but p2 is a variable of struct sStudentInfo.
In statement 2, both q1 and q2 will be a pointer to struct sStudentInfo.
Q) Can structures be passed to the functions by value?
Yes, but it is not a good programming practice because if the structure is big maybe got StackOverflow if you have a very limited amount of stack.
Q) What are the limitations of I2C interface?
- Half-duplex communication, so data is transmitted only in one direction (because of the single data bus) at a time.
- Since the bus is shared by many devices, debugging an I2C bus (detecting which device is misbehaving) for issues is pretty difficult.
- The I2C bus is shared by multiple slave devices if anyone of these slaves misbehaves (pull either SCL or SDA low for an indefinite time) the bus will be stalled. No further communication will take place.
- I2C uses resistive pull-up for its bus. Limiting the bus speed.
- Bus speed is directly dependent on the bus capacitance, meaning longer I2C bus traces will limit the bus speed.
Q) What is the Featured of CAN Protocol?
There are few features of can protocol.
- Simple and flexible in Configuration.
- CAN is a Message-Based Protocol.
- Message prioritization feature through identifier selection.
- CAN offer Multi-master Communication.
- Error Detection and Fault Confinement feature.
- Retransmission of the corrupted message automatically when the bus is idle.
Q) What is priority inversion?
Priority inversion is a problem, not a solution. Priority inversion is a situation where a high-priority task is blocked on a low-priority task using a protected shared resource. During this blockage, a medium-priority task (that does not need the shared resource) can finish its work before the high-priority task.

Q) What is priority inheritance?
In priority inheritance, a low-priority task is automatically assigned the priority of a higher priority task when it blocks on the mutex. The low-priority task is re-assigned its original priority when it releases the mutex.
Q) Significance of watchdog timer in Embedded Systems?
Using the watchdog timer you can reset your device. It is a useful tool in helping your system recover from transient failures.
Q) What Is Concatenation Operator in Embedded C?
Token Pasting Operator (##) is sometimes called a merging or combining operator. It is used to merge two valid tokens, it is the reason we called it token concatenation. See the below example code,
#include <stdio.h>
#define MERGE(token1, token2) token1##token2
int main()
{
int var1 = 10;
int var2 = 20;
int var3 = 30;
printf("%d\n", MERGE(var, 1));
printf("%d\n", MERGE(var, 2));
printf("%d\n", MERGE(var, 3));
return 0;
}
Output: 10 ,20,30
Q) What is the result of the below C code?
#include <stdio.h>
int main()
{
unsigned int x = 10 ;
int y = -30;
if(x+y > 10)
{
printf("Greater than 10");
}
else
{
printf("Less than or equals 10");
}
return 0;
}
Hint: Read this post, Signed vs Unsigned.
Q) Difference between ++*p, *p++, and *++p?
Q) What is the difference between C and embedded C?
The C standard doesn’t care about embedded, but vendors of embedded systems usually provide standalone implementations with whatever amount of libraries they’re willing to provide.
C is a widely-used general-purpose high-level programming language mainly intended for system programming. On the other side, Embedded C is an extension to the C programming language that provides support for developing efficient programs for embedded devices. It is not a part of the C language.
Following are the comparison chart for traditional C language and Embedded C:
| C Language | Embedded C Language |
|---|---|
| C is a widely-used general-purpose high-level programming language. | It is used for cross-development purposes |
| C is a high-level programming language. It maintains by the C standard committee. The C standard doesn’t care about embedded. | Embedded C is an extension to the C programming language that provides support for developing efficient programs for embedded devices. |
| C is independent of hardware and its underlying architecture. | Embedded C is dependent on the hardware architecture. |
| C is mainly used for developing desktop applications. Mainly intended for system programming. | Embedded C is used in embedded systems for microcontroller-based applications. |
Q) Can you explain the different ways of executing embedded code?
An embedded code can be executed in many ways depending on the system architecture and the memory configuration. Consider a few of them:
- In-Place Execution (XIP)
- Execution from SRAM.
- Execution from External Memory.
- JIT/Dynamic Code Loading
- Execution from Cache.
- Bare-Metal Execution
- Overlays (Banked Memory)
I hope the above Embedded C interview questions and answers help you strengthen your fundamentals and prepare confidently for embedded systems interviews. Along with the solved questions, I have also included several unsolved and real-world Embedded C interview questions that are rarely discussed online.
If you know the answers to these unsolved Embedded C questions, feel free to share them in the comment section below. Your insights could help fellow embedded engineers, freshers, and professionals gain a deeper understanding and prepare better for real interview scenarios.
1–4 Years Experience (Junior–Mid Embedded Engineer)
Focus: fundamentals + real debugging awareness
Topic: Core Embedded C & Debugging
- Why is volatile NOT sufficient for shared variables between ISR and main loop?
- If your LED blinks correctly in debug mode but fails in release mode, where do you start debugging?
- Why do embedded compilers sometimes ignore your delay loop even without optimization flags?
- What happens if an interrupt occurs while the CPU is executing a memcpy()?
- How do you find a bug using the debugger if a pointer is pointing to an illegal address?
- Why should global variables be avoided even in small embedded projects?
- What is the difference between heap and stack, and when does heap fail silently?
- How can a double pointer be useful in embedded systems?
- What is a sequence point in C, and why does it matter in embedded code?
- Is it faster to count down than count up on a microcontroller? Why?
Memory & Language Concepts:
- Difference between volatile and non-volatile memory in real products.
- Difference between Flash, EPROM, and EEPROM from a firmware perspective.
- Difference between union and structure, and where unions are dangerous.
- Is it possible to declare struct and union inside each other? When should you avoid it?
- Difference between C and Embedded C (from a hardware interaction point of view).
Communication Basics:
- Difference between UART and RS232 (beyond voltage levels).
- What is CAN and why is it message-oriented?
- Why CAN uses 120-ohm termination at both ends?
- What is bit stuffing, and what happens if it fails?
4–8 Years Experience (Senior Embedded Engineer)
Focus: concurrency, RTOS, buses, real failures
Concurrency & RTOS
- Why is disabling interrupts NOT enough to protect shared data?
- What is thread-safe code, and why most embedded code is not?
- Difference between binary semaphore and mutex — give a deadlock scenario.
- What is a spinlock, and when is it a bad idea in embedded systems?
- How many IPC mechanisms do you know, and when NOT to use queues?
- What happens if ISR execution time slowly increases over firmware revisions?
- How can compiler optimization introduce race conditions?
DMA, Memory, Performance
- What is DMA, and how can DMA break otherwise correct code?
- What hidden bugs appear when DMA + cache are enabled?
- How would you detect stack overflow on a system without MMU?
- Why does heap fragmentation appear only after days of runtime?
CAN Protocol (Automotive)
- What is CAN arbitration, and how CAN follows arbitration electrically?
- Can Standard CAN and Extended CAN coexist? Who wins arbitration?
- Difference between High-Speed CAN and Low-Speed CAN (failure behavior).
- Explain active error, passive error, and bus-off with recovery strategy.
- Why CAN uses CSMA/CA, not CSMA/CD?
- What is bit time, and how do you calculate time quanta practically?
- Types of CAN frames and when remote frame should NOT be used.
- Functions of a CAN transceiver beyond level shifting.
- Why CAN bus topology avoids star configuration in practice?
8+ Years Experience (Lead / Architect / Principal Engineer)
Focus: architecture, long-term stability, decisions
Architecture & Design
- How do you decide which firmware parts must be deterministic and which can be best-effort?
- What design mistakes make firmware impossible to unit-test later?
- How do you design firmware assuming the hardware WILL change next revision?
- What firmware decisions increase long-term maintenance cost more than hardware cost?
- When would you intentionally violate MISRA rules, and how do you justify it?
Reliability & Field Failures
- Describe a bug that appears only after weeks/months of uptime.
- Why is adding logging sometimes more dangerous than helpful?
- How do you design firmware so a single peripheral failure does NOT reboot the system?
- How do you safely recover from bus-off CAN state in a safety-critical system?
- How do you ensure firmware survives unexpected resets during flash updates?
Powerful Questions
- How do you debug a system that fails only in customer environment?
- How do you design firmware to support post-production diagnostics?
- What makes embedded software production-ready, not just “working”?
- How do you decide between RTOS vs super-loop for a new product?
- How do you prove a system is real-time and not just fast?
Recommended Post
- Can protocol interview Questions.
- HDLC Protocol introduction.
- 100 C interview Questions.
- Embedded system interview Questions with Answers
- I2C interview Questions
- Interview questions on bitwise operators in C
- C++ Interview Questions.
- 10 questions about dynamic memory allocation.
- File handling in C.
- Pointer in C.
- C format specifiers.
You can see this link for more detail about ISR.